Prometheus monitoring and alerting
Prometheus is an open-source systems monitoring and alerting toolkit. Prometheus collects and stores metrics as time series data, i.e. metrics information is stored with the timestamp at which it was recorded, alongside optional key-value pairs called labels.
Users can measure the internal status of a QuestDB instance via an HTTP endpoint
exposed by QuestDB at port 9003. This document describes how to enable metrics
via this endpoint, how to configure Prometheus to scrape metrics from a QuestDB
instance, and how to enable alerting from QuestDB to Prometheus Alertmanager.
Prerequisites#
QuestDB must be running and accessible. You can do so from Docker, the binaries, or Homebrew for macOS users.
Prometheus can be installed using homebrew, Docker, or directly as a binary. For more details, refer to the official Prometheus installation instructions.
Alertmanager can be run using Docker or Quay, or can be built from source by following the build instructions on GitHub.
Scraping Prometheus metrics from QuestDB#
QuestDB has a /metrics HTTP endpoint on port 9003 to expose Prometheus
metrics. Before being able to query metrics, they must be enabled via the
metrics.enabled key in server configuration:
When running QuestDB via Docker, port 9003 must be exposed and the metrics
configuration can be enabled via the QDB_METRICS_ENABLED environment variable:
To verify that metrics are being exposed correctly by QuestDB, navigate to
http://<questdb_ip>:9003/metrics in a browser, where <questdb_ip> is the IP
address of an instance, or execute a basic curl like the following example:
To configure Prometheus to scrape these metrics, provide the QuestDB instance IP
and port 9003 as a target. The following example configuration file
questdb.yml assumes there is a running QuestDB instance on localhost
(127.0.0.1) with port 9003 available:
Start Prometheus and pass this configuration on launch:
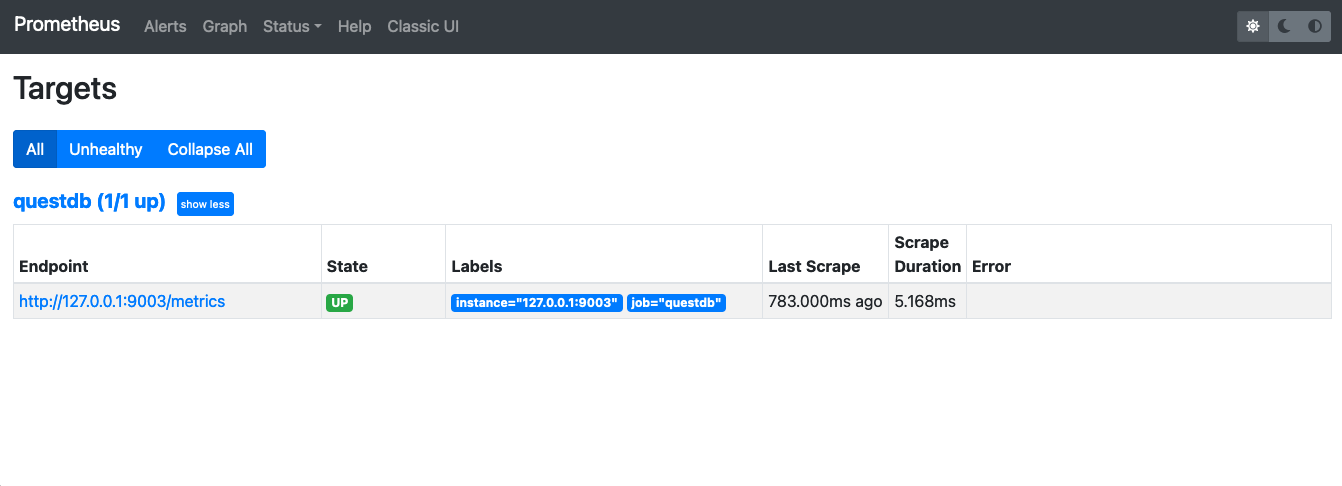
Prometheus should be available on 0.0.0.0:9090 and navigating to
http://0.0.0.0:9090/targets should show that QuestDB is being scraped
successfully:
In the graphing tab of Prometheus (http://0.0.0.0:9090/graph), autocomplete
can be used to graph QuestDB-specific metrics which are all prefixed with
questdb_:
The following metrics are available:
| Metric | Type | Description |
|---|---|---|
questdb_commits_total | counter | Number of total commits of all types (in-order and out-of-order) executed on the database tables. |
questdb_o3_commits_total | counter | Number of total out-of-order (O3) commits executed on the database tables. |
questdb_committed_rows_total | counter | Number of total rows committed to the database tables. |
questdb_physically_written_rows_total | counter | Number of total rows physically written to disk. Greater than committed_rows when out-of-order ingestion is enabled. Write amplification is questdb_physically_written_rows_total / questdb_committed_rows_total. |
questdb_rollbacks_total | counter | Number of total rollbacks executed on the database tables. |
questdb_json_queries_total | counter | Number of total REST API queries, including retries. |
questdb_json_queries_completed | counter | Number of successfully executed REST API queries. |
questdb_unhandled_errors_total | counter | Number of total unhandled errors occurred in the database. Such errors usually mean a critical service degradation in one of the database subsystems. |
questdb_jvm_major_gc_count | counter | Number of times major JVM garbage collection was triggered. |
questdb_jvm_major_gc_time | counter | Total time spent on major JVM garbage collection in milliseconds. |
questdb_jvm_minor_gc_count | counter | Number of times minor JVM garbage collection pause was triggered. |
questdb_jvm_minor_gc_time | counter | Total time spent on minor JVM garbage collection pauses in milliseconds. |
questdb_jvm_unknown_gc_count | counter | Number of times JVM garbage collection of unknown type was triggered. Non-zero values of this metric may be observed only on some, non-mainstream JVM implementations. |
questdb_jvm_unknown_gc_time | counter | Total time spent on JVM garbage collection of unknown type in milliseconds. Non-zero values of this metric may be observed only on some, non-mainstream JVM implementations. |
questdb_memory_tag_MMAP_DEFAULT | gauge | Amount of memory allocated for mmaped files. |
questdb_memory_tag_NATIVE_DEFAULT | gauge | Amount of allocated untagged native memory. |
questdb_memory_tag_MMAP_O3 | gauge | Amount of memory allocated for O3 mmapped files. |
questdb_memory_tag_NATIVE_O3 | gauge | Amount of memory allocated for O3. |
questdb_memory_tag_NATIVE_RECORD_CHAIN | gauge | Amount of memory allocated for SQL record chains. |
questdb_memory_tag_MMAP_TABLE_WRITER | gauge | Amount of memory allocated for table writer mmapped files. |
questdb_memory_tag_NATIVE_TREE_CHAIN | gauge | Amount of memory allocated for SQL tree chains. |
questdb_memory_tag_MMAP_TABLE_READER | gauge | Amount of memory allocated for table reader mmapped files. |
questdb_memory_tag_NATIVE_COMPACT_MAP | gauge | Amount of memory allocated for SQL compact maps. |
questdb_memory_tag_NATIVE_FAST_MAP | gauge | Amount of memory allocated for SQL fast maps. |
questdb_memory_tag_NATIVE_LONG_LIST | gauge | Amount of memory allocated for long lists. |
questdb_memory_tag_NATIVE_HTTP_CONN | gauge | Amount of memory allocated for HTTP connections. |
questdb_memory_tag_NATIVE_PGW_CONN | gauge | Amount of memory allocated for PGWire connections. |
questdb_memory_tag_MMAP_INDEX_READER | gauge | Amount of memory allocated for index reader mmapped files. |
questdb_memory_tag_MMAP_INDEX_WRITER | gauge | Amount of memory allocated for index writer mmapped files. |
questdb_memory_tag_MMAP_INDEX_SLIDER | gauge | Amount of memory allocated for indexed column view mmapped files. |
questdb_memory_tag_NATIVE_REPL | gauge | Amount of memory mapped for replication tasks. |
questdb_memory_free_count | gauge | Number of times native memory was freed. |
questdb_memory_mem_used | gauge | Current amount of allocated native memory. |
questdb_memory_malloc_count | gauge | Number of times native memory was allocated. |
questdb_memory_realloc_count | gauge | Number of times native memory was reallocated. |
questdb_memory_jvm_free | gauge | Current amount of free Java memory heap in bytes. |
questdb_memory_jvm_total | gauge | Current size of Java memory heap in bytes. |
questdb_memory_jvm_max | gauge | Maximum amount of Java heap memory that can be allocated in bytes. |
questdb_json_queries_cached | gauge | Number of current cached REST API queries. |
questdb_pg_wire_select_queries_cached | gauge | Number of current cached PGWire SELECT queries. |
questdb_pg_wire_update_queries_cached | gauge | Number of current cached PGWire UPDATE queries. |
All of the above metrics are volatile, i.e. they're collected since the current database start.
Configuring Prometheus Alertmanager#
QuestDB includes a log writer that sends any message logged at critical level
(by default) to Prometheus
Alertmanager over a
TCP/IP socket connection. To configure this writer, add it to the writers
config alongside other log writers. Details on logging configuration can be
found on the
server configuration documentation.
Alertmanager may be started via Docker with the following command:
To discover the IP address of this container, run the following command which
specifies alertmanager as the container name:
To run QuestDB and point it towards Alertmanager for alerting, first create a
file ./conf/log.conf with the following contents. 172.17.0.2 in this case is
the IP address of the docker container for alertmanager that was discovered by
running the docker inspect command above.
Start up QuestDB in Docker using the following command:
When alerts are successfully triggered, QuestDB logs will indicate the sent and received status:
info
The template used by QuestDB for alerts is user-configurable and is described in more detail in the server configuration documentation.